iPER dataset
ShanghaiTech University
[Download(OneDrive)] [Download(BaiduYun)]

Introduction
To evaluate the performances of our proposed method of motion imitation, appearance transfer and novel view synthesis, we build a new dataset with diverse styles of clothes, named as Impersonator (iPER) dataset. There are 30 subjects of different conditions of shape, height and gender. Each subject wears different clothes and performs an A-pose video and a video with random actions. Some subjects might wear multiple clothes, and there are 103 clothes in total. The whole dataset contains 206 video sequences with 241,564 frames. We split it into training/testing set at the ratio of 8:2 according to the different clothes.
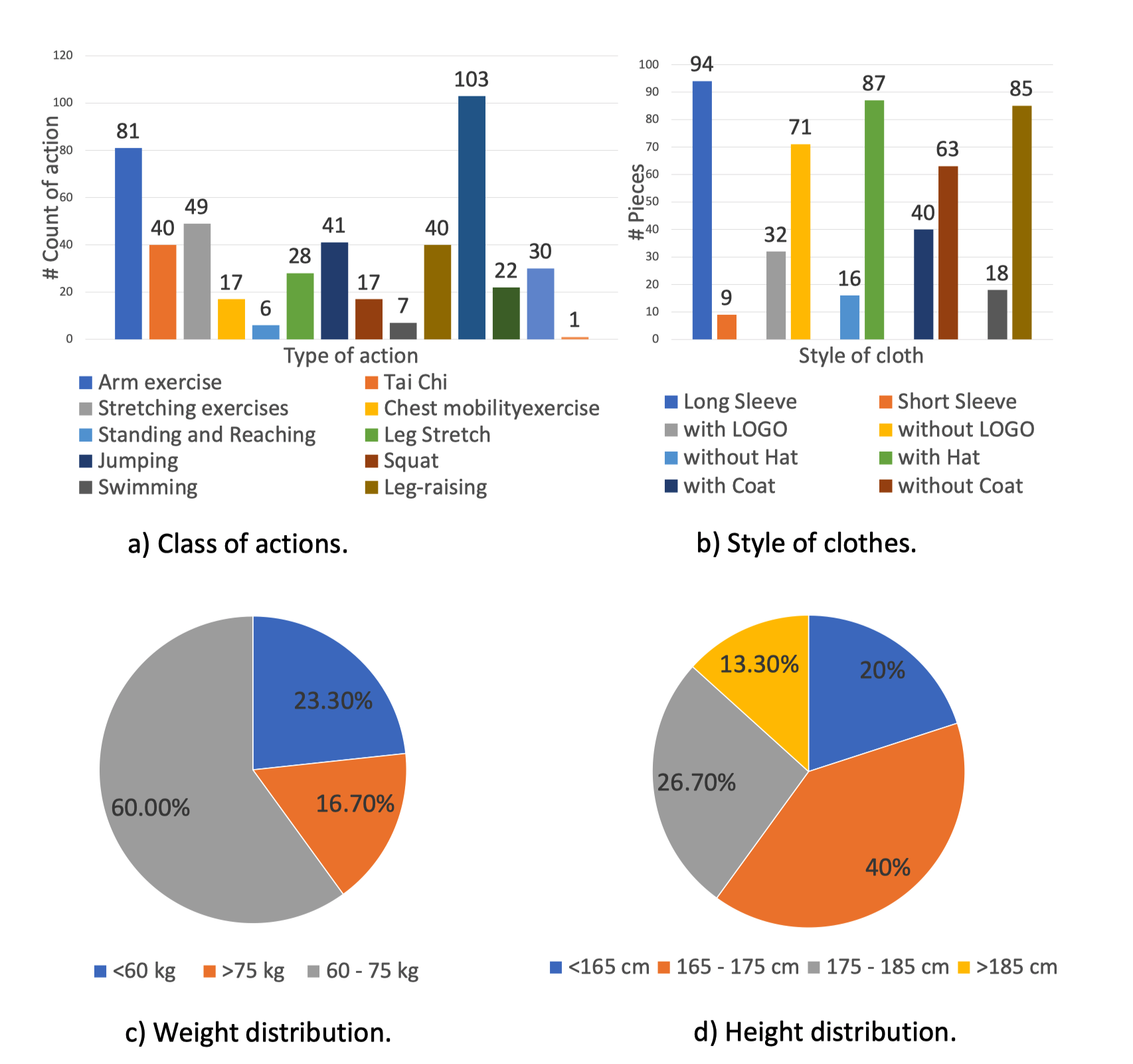
Details of Impersonator (iPER) dataset as shown in above. (a) shows the class of actions and their number of occurrences. (b) shows the styles of clothes. (c) and (d) are the distributions of weight and height of all actors. There are 30 actors in total.
Action Demo (A pose)
Action Demo (Random pose)
Dataset Format
There are 206 videos in total, all of those have same style, as "xxx_yyy_zzz.mp4", where:Evaluation Metric
We propose an evaluation protocol of testing set of iPER dataset and it is able to indicate the performance of different methods in terms of different aspects. The details are listed in followings:
(1) In each video, we select three images as source images (frontal, sideway and occlusive) with different degrees of occlusion. The frontal image contains the most information, while the sideway will drop out some information, and occlusive image will introduce ambiguity.
(2) For each source image, we perform self-imitation that actors imitate actions from themselves. SSIM and Learned Perceptual Similarity (LPIPS) are the evaluation metrics in self-imitation setting.
(3) Besides, we also conduct cross-imitation that actors imitate actions from others. We use Inception Score (IS) and Fr´echet Distance on a pre-trained person-reid model, named as FReID, to evaluate the quality of generated images.
Agreement
1. The iPER dataset is available for non-commercial research purposes only. The members of the SVIP Lab recruited subjects and recorded the videos in a controlled setting, and all subjects signed the protocol to permit recordings of them to be made public and used for research purposes.
2. You agree not to reproduce, duplicate, copy, sell, trade, resell or exploit for any commercial purposes, any portion of the images and any portion of derived data.
3. You agree not to further copy, publish or distribute any portion of the iPER dataset. Except, for internal use at a single site within the same organization it is allowed to make copies of the dataset.
4. The SVIP Lab reserves the right to terminate your access to the iPER dataset at any time.
Citation
If you find this useful, please cite our work as follows:
@InProceedings{lwb2019,
title={Liquid Warping GAN: A Unified Framework for Human Motion Imitation, Appearance Transfer and Novel View Synthesis},
author={Wen Liu and Zhixin Piao, Min Jie, Wenhan Luo, Lin Ma and and Shenghua Gao},
booktitle={The IEEE International Conference on Computer Vision (ICCV)},
year={2019}
}